Artificial Intelligence (AI) has already transformed healthcare with its powerful capabilities in data analysis, diagnostics, and personalized treatment plans. However, the development of mobile AI apps is now pushing the boundaries even further by bringing advanced medical research tools to the palm of your hand. These mobile AI applications offer unprecedented convenience and accessibility, enabling both healthcare professionals and patients to engage with cutting-edge medical research from virtually anywhere.
One standout example is Ada Health, an AI-powered mobile app that uses machine learning algorithms to assist users in identifying potential health conditions based on symptoms entered into the app. By analyzing large datasets from clinical records, medical literature, and symptom tracking, the app offers personalized insights and recommendations for further medical consultation. Its adaptive learning model ensures that the app continually improves its accuracy as more data is fed into the system, providing users with more precise health evaluations.
In the realm of medical research, mobile AI apps facilitate real-time data collection from patients, enabling researchers to track health conditions, disease progression, and treatment outcomes more effectively. AI-powered mobile platforms have been instrumental in clinical trials, where participants use these apps to log daily symptoms, medication usage, and lifestyle habits. This influx of real-time data allows researchers to make faster, data-driven decisions and accelerate the research process.
Furthermore, mobile AI apps hold immense potential for developing countries and remote areas, where access to healthcare infrastructure is limited. By offering AI-driven medical assistance and diagnostics, these apps democratize healthcare, making advanced medical tools accessible to people around the globe.
References:
Ada Health. (n.d.). How AI-powered mobile health apps are transforming patient care. https://ada.com
National Institutes of Health. (2021). AI in mobile health: Revolutionizing medical research and diagnostics. https://www.nih.gov
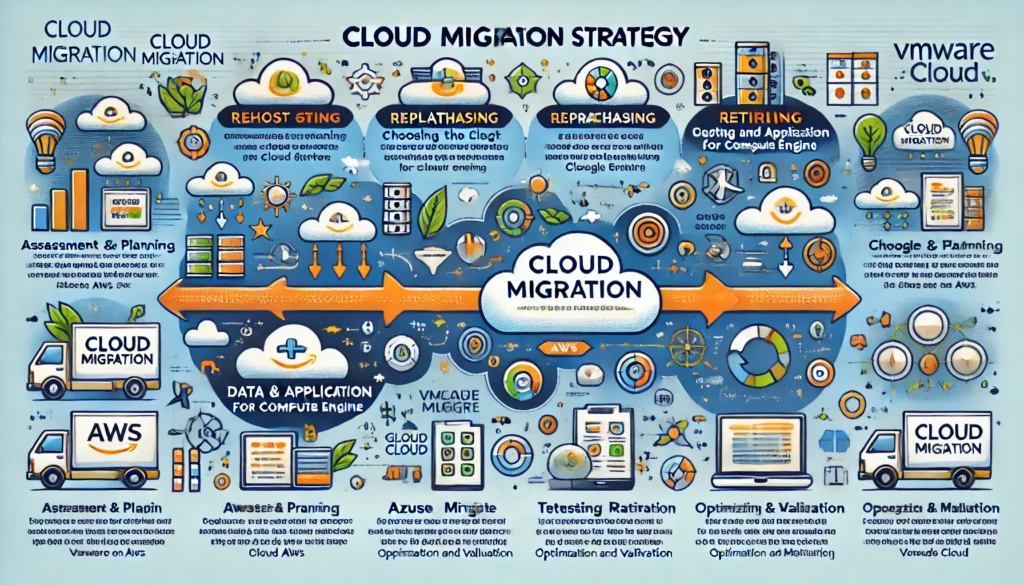
Cloud migration refers to the process of moving data, applications, and other business elements from on-premise infrastructure or legacy systems to cloud computing environments. Cloud migration can also involve moving resources from one cloud provider to another (cloud-to-cloud migration) or switching from a public cloud to a private cloud. This shift is driven by the desire for scalability, flexibility, cost savings, and enhanced security that cloud computing offers.
Cloud Migration Strategy
A cloud migration strategy outlines the approach an organization takes to move its resources to the cloud. Common strategies include:
1.Rehosting (“Lift and Shift”): Moving applications directly to the cloud with minimal changes.
2.Replatforming: Making slight optimizations to the applications during migration to better utilize cloud features.
3.Repurchasing: Switching to a new cloud-native product, such as moving from a traditional CRM to a SaaS-based one.
4.Refactoring: Rebuilding applications from scratch using cloud-native technologies to maximize performance, scalability, and agility.
5.Retiring: Identifying and retiring outdated or unnecessary applications in the migration process.
6.Retaining: Keeping some applications on-premise, often due to regulatory concerns or technical requirements.
Cloud Migration Process
1. Assessment and Planning: Analyze current workloads and infrastructure to determine which applications should move to the cloud and in what order. Consider factors like performance, security, compliance, and costs.
2. Choosing the Right Cloud Environment: Select between public, private, or hybrid cloud environments based on the business’s needs. Providers like AWS, Azure, and Google Cloud offer different services and pricing structures.
3. Data and Application Migration: Execute the actual transfer of data and applications. This step may involve reconfiguring applications to ensure they work in the new cloud environment.
4. Testing and Validation: After migration, test applications and services for functionality, performance, and security to ensure they meet the desired outcomes.
5. Optimization and Monitoring: Fine-tune the new environment for performance and cost-efficiency. Set up continuous monitoring to track resource usage, performance metrics, and potential security risks.
Cloud Migration Tools
Several tools can help automate and simplify the migration process:
1. AWS Migration Hub: Provides tracking and management for migrations to AWS.
2. Azure Migrate: Microsoft’s tool for assessing and migrating on-premise systems to Azure.
3. Google Cloud Migrate for Compute Engine: A tool for migrating workloads to Google Cloud Platform.
4. CloudEndure: A disaster recovery and migration tool that supports multi-cloud migrations.
5. VMware Cloud on AWS: Facilitates migration of VMware-based workloads to AWS.
Cloud migration offers numerous benefits, but a well-structured strategy is essential to minimize disruption, ensure data integrity, and achieve business goals.
References:
Amazon Web Services. (n.d.). Cloud migration strategies. AWS. https://aws.amazon.com/cloud-migration
Google Cloud. (n.d.). Migration to Google Cloud. Google Cloud. https://cloud.google.com/migrate
Microsoft Azure. (n.d.). Cloud migration. Azure. https://azure.microsoft.com/en-us/solutions/cloud-migration
In today’s interconnected world, data flows freely across borders, raising concerns about privacy, security, and national control. Data localization and data sovereignty have become critical issues, especially as organizations increasingly adopt cloud services. These concepts are particularly relevant for countries seeking to assert greater control over data generated within their borders and for organizations striving to comply with various regulations.
What is Data Localization?
Data localization refers to regulations that require organizations to store and process data within the country’s borders where it was collected. This means that data generated in one country must remain within that jurisdiction and cannot be transferred or processed abroad without special permissions. These laws are often driven by concerns over national security, privacy, and data protection.
Many countries have implemented data localization requirements to maintain control over sensitive data and to ensure that data remains subject to their own regulatory environments. For example, the European Union’s General Data Protection Regulation (GDPR) imposes strict requirements on data transfer outside the EU to ensure adequate protection levels. Similarly, India’s Personal Data Protection Bill mandates that critical personal data be stored and processed only within India.
What is Data Sovereignty?
Data sovereignty refers to the concept that data is subject to the laws and regulations of the country in which it is stored. This concept becomes particularly important when using cloud service providers, as data stored in the cloud might reside in multiple locations across different countries. As a result, the data becomes subject to multiple legal frameworks, which can complicate compliance efforts for businesses.
For instance, the United States’ Cloud Act allows the U.S. government to access data stored by U.S.-based cloud providers, regardless of where the data is located. This raises sovereignty concerns for countries that fear foreign governments could access sensitive data stored in the cloud.
Challenges in the Cloud Space
For businesses leveraging cloud services, data localization and sovereignty present several challenges:
1. Compliance with Diverse Regulations: Different countries have varying laws regarding data protection, localization, and cross-border data transfers. Navigating this regulatory maze can be difficult, especially for global organizations.
2. Cost Implications: Setting up local data centers to comply with localization laws can be costly. Companies may also face increased operational complexities as they ensure data segregation and compliance in multiple jurisdictions.
3. Cloud Provider Selection: Organizations need to carefully select cloud providers that offer solutions aligning with local regulations. Many leading cloud providers, such as AWS, Microsoft Azure, and Google Cloud, now offer region-specific services to address these concerns.
Conclusion
As cloud adoption continues to grow, data localization and sovereignty will remain critical factors for businesses and governments alike. To stay compliant, organizations must stay informed about the evolving regulatory landscape and work closely with cloud providers to ensure their data is handled securely and lawfully.
References
European Union. (2016). General Data Protection Regulation (GDPR). https://gdpr.eu
Government of India. (2019). Personal Data Protection Bill. Ministry of Electronics and Information Technology. https://meity.gov.in/writereaddata/files/Personal_Data_Protection_Bill,2019.pdf
U.S. Department of Justice. (2018). Clarifying Lawful Overseas Use of Data (CLOUD) Act. https://www.justice.gov/cloud-act
Cloud computing has become a key enabler for artificial intelligence (AI) development, offering the scalability, flexibility, and power required to process large datasets and perform complex calculations. The most critical aspect of AI is data, and cloud computing provides seamless access to vast storage and computational resources that allow AI systems to process, analyze, and learn from this data in real-time.
One of the key advantages of cloud computing is its scalability. AI models, particularly in machine learning and deep learning, require immense computational power. Cloud platforms like AWS, Google Cloud, and Microsoft Azure allow organizations to scale resources up or down based on demand, eliminating the need for expensive, on-premise hardware.
Additionally, cloud platforms support collaborative AI development, making it easier for teams worldwide to work on AI projects together. This accelerates innovation by enabling fast access to shared datasets, tools, and AI development frameworks.
Lastly, cloud computing enhances the deployment of AI solutions. Whether it’s integrating AI into existing applications or building new AI-driven services, the cloud provides flexible infrastructure, enabling fast, global deployment of AI technologies.
In conclusion, cloud computing empowers AI by providing scalable resources, collaborative environments, and rapid deployment capabilities, making it a crucial foundation for AI development.
In the fast-evolving field of artificial intelligence (AI), data remains at the core of every innovation and advancement. One of the most exciting developments in recent years is Generative AI, a branch of AI that creates content—be it text, images, or even entire virtual environments—based on vast datasets. Generative AI models, like OpenAI’s GPT-4, have revolutionized the way we think about data, creativity, and problem-solving.
The Rise of Generative AI
Generative AI refers to AI models that can create new content from patterns and information gleaned from massive datasets. Unlike traditional AI, which focuses on task automation or pattern recognition, generative models generate new outputs—such as human-like text, artwork, or even code—based on the input data they have learned from. This ability to generate content has implications across industries, from creative writing to complex scientific research.
For example, OpenAI’s GPT models have demonstrated how language models trained on enormous datasets can generate coherent essays, perform translations, and even answer complex questions. The core ingredient for these breakthroughs? Data. Without access to diverse, high-quality data, these models would be limited in their ability to generate meaningful or useful outputs.
Data: The Lifeblood of AI Models
The success of generative AI hinges on access to massive amounts of high-quality, labeled data. AI models learn by identifying patterns within these datasets, making data not just fuel but a foundational resource. The quality, diversity, and quantity of the data directly influence the accuracy, creativity, and generalizability of AI models.
1. Data Diversity: For AI to generate new and useful outputs, the datasets need to encompass a wide variety of examples. This is especially important for models like GPT-4, which generate human-like text or conduct complex tasks. Data diversity ensures that models are less biased and can cater to a broader range of scenarios.
2. Real-Time Data: The integration of real-time data into AI systems is becoming increasingly important. Companies like Tesla, which uses real-time data from its fleet of vehicles to improve its autonomous driving algorithms, exemplify how AI models are increasingly leveraging up-to-the-minute information to make better decisions and generate more accurate outputs.
3. Ethical Considerations: As the reliance on data grows, so do concerns about the ethical use of AI. Issues like data privacy, bias in AI algorithms, and the ownership of generated content are at the forefront of AI discussions. Ensuring that AI models are trained on ethically sourced and diverse data is crucial for responsible AI development.
Generative AI in 2024: A Case Study
One of the most significant developments in generative AI this year is the emergence of AI-generated content in creative industries, from music composition to visual arts. Platforms like MidJourney and Runway are leveraging generative AI to assist artists in creating new and original content, blurring the lines between human creativity and machine learning.
Moreover, AI-driven text generators are increasingly being used in businesses for content creation, marketing, and personalized customer service. The ability to generate human-like conversations at scale is transforming industries like retail and customer support.
The Future: AI’s Dependency on Data
As we move deeper into the age of generative AI, the reliance on data will only intensify. Companies and organizations that can harness diverse, high-quality datasets will lead the charge in AI development, while those without access to this critical resource will lag behind. The next wave of innovations in AI—from autonomous agents to personalized healthcare solutions—will depend not just on cutting-edge algorithms but on the data that powers them.
Conclusion
The intersection of data and AI continues to shape the future of technology and industry. Generative AI, in particular, is proving that the combination of vast datasets and advanced algorithms can unlock unprecedented creative potential. As AI becomes increasingly integrated into our daily lives, data will remain the key to unlocking its full potential.